想象一下,一个孩子参观一个农场,第一次看到绵羊和山羊。他们的父母指出哪个是什么,帮助孩子学会区分两者。但如果孩子在回访时没有得到这样的指导,会发生什么呢?他们还能把他们区分开来吗?
神经科学家Franziska Br?ker正在研究人类和机器如何在没有监督的情况下学习——就像一个孩子自己学习一样——并发现了一个难题:无监督的学习可以帮助或阻碍进步,这取决于某些条件。该论文发表在《认知科学趋势》杂志上。
在机器学习的世界里,算法在无监督的数据上茁壮成长。它们在没有明确标签的情况下分析大量信息,但仍然设法学习有用的模式。这一成功引发了一个问题:如果机器可以通过这种方式学习得这么好,为什么人类在类似的情况下会挣扎?
根据最近的研究,答案可能在于我们如何在没有反馈的情况下做出预测并加强预测。换句话说,结果取决于我们对任务的内在理解与任务实际要求的匹配程度。
研究表明,人类和机器一样,通过预测来理解新信息。例如,如果有人认为毛茸茸是绵羊和山羊之间的关键区别,他们可能会错误地将毛茸茸的山羊归类为绵羊。当没有人在身边纠正这个错误时,他们错误的预测就会被强化,这使得学习正确的区别变得更加困难。这种“自我强化”的过程会产生滚雪球效应:如果他们最初的猜测是正确的,他们的学习能力就会提高——但如果他们的猜测是错误的,他们可能会陷入错误信念的循环中。
这种现象不仅适用于动物识别。从学习演奏一种乐器到掌握一门新语言,都可以看到同样的动态。如果没有指导或反馈,人们往往会强化不正确的方法,使他们的错误在以后更难纠正。
研究表明,当一个人的初步理解已经与任务相一致时,无监督学习效果最好。对于更难的任务,比如学习复杂的语言规则或困难的运动技能,反馈对于避免这些陷阱至关重要。
最后,无监督学习的好坏参半的结果说明了一个更大的问题:没有反馈的学习是否有效并不重要,重要的是何时以及如何学习。随着人类和机器在更复杂的环境中继续学习,理解这些细微差别可能会带来更好的教学方法、更有效的训练工具,甚至可能是更智能的算法,它们可以像我们一样更好地自我纠正。
虽然实验室研究揭示了无监督学习的各种结果,但理解其在现实世界学习场景中的含义需要检查专业知识获取,这源于不同程度的监督下的广泛学习。
例如,放射科医生在职业生涯的早期得到结构化的反馈,但逐渐失去了明确的监督指导。如果单靠无监督学习就能培养专业知识,我们就会期待持续的进步,但证据表明并非如此。
批评人士认为,经验并不一定能预测专业知识,因为它只能反映资历,而不能反映实质性的技能提高。偏见,如确认偏见,会通过偏爱与先入为主的信息来进一步扭曲无监督学习,最终阻碍进步。
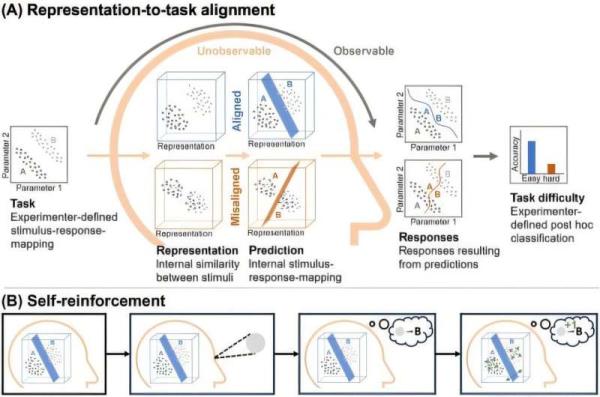
相反,对决策的定期反馈似乎是稳定改进所必需的。这与表征-任务一致性框架一致,该框架假设初始反馈有助于学习者在有效地自我调节学习之前建立准确的心理表征。
例如,在运动技能学习中,在学习过程的早期取消反馈可能会导致表现下降,而在学习者的预测更准确的时候收回反馈有助于保持甚至提高表现。这突出表明,专业知识不仅需要经验,还需要在关键学习阶段的及时监督。
无监督学习通常由自我强化机制驱动,学习者使用自己的预测而不是外部验证。这种形式的学习在感知学习和类别学习中得到了很好的探索,其中Hebbian模型展示了无监督学习如何根据学习者的表征与任务的一致程度来提高或降低性能。
这些模型已经成功地解释了半监督分类,例如儿童对语言标签的习得,这表明自我强化可以塑造学习轨迹。
然而,缺乏反馈,特别是在获得专门知识方面,可能导致不正确的预测长期存在,正如刻板印象所表明的那样。如果没有外部纠正,个体可能会强化自己的错误预测,这是一种由建构主义编码假设模拟的现象。
这可能导致持续的错误,因为即使在没有提供反馈的情况下,操作也被视为有效,强调了选择性反馈在缓和无监督学习中的作用。
自我强化需要独立于外部监督的内部学习信号。虽然通过外部反馈(如奖励和惩罚)进行学习的神经基础已经被很好地理解,但控制自我生成反馈的机制却不太清楚。
新兴研究表明,在外部反馈处理过程中活跃的大脑区域也会在推断反馈过程中活跃,比如学习者强化自己的选择时。即使在没有外部反馈的情况下,对自己决定的信心似乎也是自我强化的关键驱动因素,而主观奖励可以通过强化过去的决定来塑造学习轨迹。
这些内部反馈机制可能会导致学习者陷入“学习陷阱”,在那里他们停止探索其他策略,而只专注于利用他们过去的选择。神经影像学研究表明,偏好只会在记住的选择中更新,这进一步支持了内部反馈在指导无监督学习中的作用。
此外,神经重放——大脑在休息时重新激活过去经历的过程——与自我强化有关,强调了它在没有外部指导的情况下精炼心理表征的作用。
专业文献,以及对无监督学习的对照研究,都支持这样一种观点,即基于学习者的心理表征和手头任务之间的一致性,自我强化可以提高或阻碍表现。虽然无监督学习有潜力,但它并不是灵丹妙药。相反,它的有效性取决于现有知识、内部信号和任务结构之间复杂的相互作用。
未来的研究应进一步探索无监督自我强化与外部监督信号之间的关系,特别是在现实世界的学习环境中。这包括研究这些机制如何在人类学习中相互作用,这可能涉及一个统一的学习系统,而不是人工智能中经常使用的独特的、特定于任务的算法。
整合神经科学、心理学和机器学习的见解将有助于开发更全面的人类学习模型,从而导致更好地支持终身学习的教学设计,并防止对错误结论的过度自信。
最终,了解无监督学习的动态,包括其潜在的缺陷,将增强教育方法并支持各个领域专业知识的发展。通过平衡自我强化和关键的外部反馈,我们可以优化学习系统,培养深入、持久的专业知识,同时避免无监督的过度自信的陷阱。
更多信息:Franziska Br?ker等人,揭秘无监督学习:它是如何帮助和伤害的,认知科学趋势(2024)。引文:无反馈学习:神经科学家帮助揭示无监督学习对人类和机器的影响(2024年,10月18日)检索自2024年10月20日https://medicalxpress.com/news/2024-10-feedback-neuroscientist-uncover-unsupervised-humans.html此文档受版权保护。除为私人学习或研究目的而进行的任何公平交易外,未经书面许可,不得转载任何部分。内容仅供参考之用。
为您推荐:
- 洲际酒店集团将把越南的酒店网络从16家扩大到40家 2025-05-28
- “我无视英国政府让我参观巴西贫民窟的警告——这不是我想要的” 2025-05-28
- 使用人工智能修复的披头士乐队的最后一首歌有望获得格莱美奖 2025-05-28
- EuroDASS合作伙伴揭示了欧洲战斗机的电子战进展 2025-05-28
- NMDC集团在2024年前9个月实现净利润22亿迪拉姆 2025-05-27
- 流行的肥料“创造最健康的花园”——而且不需要花你一分钱 2025-05-27